For assistance, please
Stay in touch by signing up for our Data Services newsletter.
If you've interacted with us before, please tell us how we did.
Bobst Library, 5th floor
Mondays: 10am - 5pm
Tuesdays: 10am - 5pm
Wednesdays: 10am - 5pm
Thursdays: 10am - 5pm
Fridays: 10am - 5pm
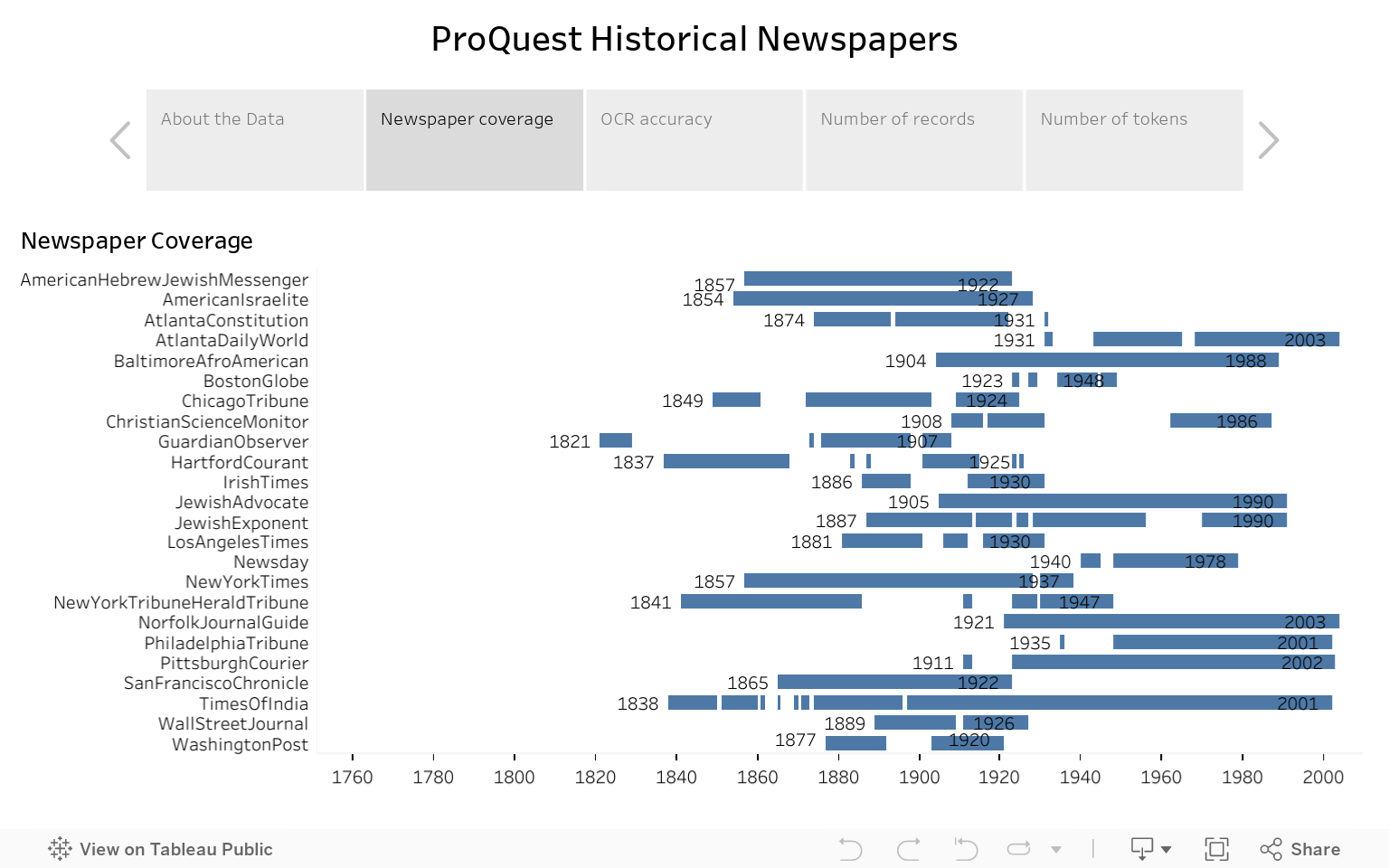
The ProQuest Historical Newspapers text-as-data collection consists of approximately 99.1 million XML files capturing the full text and a number of metadata fields for 26 newspaper titles found in the ProQuest historical newspapers database collection. The titles and years of coverage found in this collection are:
Note that this collection is not updated and additional titles or newer issues are not being added at this time. For a more complete access to the full text of ProQuest's newspaper holdings, consider using ProQuest TDM Studio access.
The collection is available to members of the NYU community only.
Each XML file consists of the metadata, identifiers, and full text of one article within a single newspaper issue. The files are arranged on the access points below by newspaper title, and within each newspaper directory, in multiple zipped files (.zip format). Each compressed file contains multiple XML files. A README file is included with the collection with further details about the file structure.
There are two access points:
ds_collections Research Workspace share on any local computer on the NYU network (i.e. on campus or on NYU VPN if off campus). Follow the instructions for how to access Research Workspace, using ds_collections as the project name. The collection will be found at ds_collections/proquest/proquest_hnp./scratch/work/public/proquest/proquest_hnp. To request an HPC account (faculty sponsorship is required), visit the HPC homepage.You can preview the data quality and availability via the dashboard below. OCR quality was scored on a per-article basis, based on the percentage of the tokens in an article that are in the large curated corpus of attested words found in the HathiTrust digital library.
Additional documentation related to this collection is available on the guide prepared by ProQuest.